EC2 instances are already grouped into five basic types, which are optimized for different purposes. These can, however, be further refined through customization options.
A quick refresher of AWS EC2 instance types
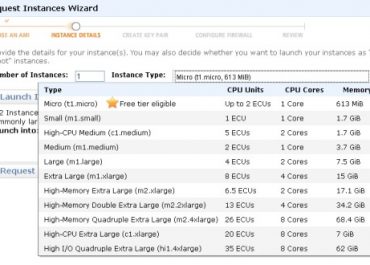
AWS EC2 instance types are grouped into five “families”. These are:
- General purpose – A, M and T
- Compute optimized – C
- Memory optimized – R, U, X and Z
- Storage optimized – D, H and I
- Accelerated computing – F, G and P
The names of each instance type follow this naming convention:
Instance type, instance generation, (additional capabilities).size. For example c5d.large
- The extended capabilities currently include
- A AMD EPYC processors
- D NVMe-based SSD disk space
- E Extended memory
- N Enhanced networking (up to 100Gbps)
- S Smaller amounts of vCPU and memory
The exceptions to this rule are the Bare Metal U and I instances.
Optimizing AWS EC2 instances for vCPU
This is exactly what it sounds like. You can adjust the default number of vCPUs and turn hyperthreading on and off.
Optimizing AWS EC2 instances for graphics with the Elastic Graphics Accelerator
Strictly speaking, if you really want to optimize AWS EC2 instances for graphics then you should choose one of the “G” options, which have been specifically created for that purpose. On the other hand, the G instances are some of the most expensive AWS EC2 instance types and, understandably, people might grudge paying for them if they don’t really need all that graphics acceleration power.
You can split the difference by adding using the Elastic Graphics Accelerator to add up to 8Gb of graphics memory to a wide range of EC2 instance types (note you do not get the benefit of the full graphics card as you do with the G instance types). You need to do this when an instance is opened (in other words, you can’t add the Elastic Graphics Accelerator to an instance which is already running) and the Elastic Graphics Accelerator is automatically terminated along with the instance.
You can only use the Elastic Graphics Accelerator once per instance, but frankly if you were thinking about using the Elastic Graphics Accelerator more than once, you should probably be paying for a proper G instance in any case.
Optimizing AWS EC2 instances for throughput with Elastic Inference
The “P” instances are optimized for GPU-intensive computing, but again, they are far from the most budget-friendly instances AWS has to offer. You therefore typically want to limit them to when they are really needed and reach for Elastic Inference when they are not.
Generally speaking, if you’re running machine-learning training, then you’re probably going to need to pay up for a proper “P” instance type. If, however, you’re just running a machine-learning trained module for making predictions, then you’re probably going to have fewer inputs and hence need less GPU power. You are therefore more likely to be able to get away with using Elastic Inference to boost the GPU power of “standard” EC2 instances.
As with the Elastic Graphics Accelerator, you need to activate Elastic Inference when you open a new instance (in other words, you cannot add Elastic Inference to an instance which is already running) and the Elastic Inference automatically terminates when the instance is closed.
Also as with the Elastic Graphics Accelerator, you can only apply Elastic Inference once per instance. This is a bit of a shame as Elastic Inference ranges from 1 to 32 trillion floating-point operations per second, whereas P3 instances currently start at 125 trillion floating-point operations per second, so it would have been nice to have been able to scale up a bit more before paying up for a proper P instance. Even as it stands, however, you still have quite a bit of flexibility to increase the GPU power at a reasonable cost.
Optimizing for privacy with dedicated resources
AWS has an interesting set up in that it is a public cloud that can essentially do double duty as a private cloud by allowing users to assign themselves dedicated resources. You may already be aware of EC2 Dedicated Host. This is when a physical server is entirely dedicated to one AWS account and virtualization software is then used to divide the server’s resources into AWS EC2 dedicated instances. This approach is often used in Bring Your Own Licence scenarios and also for organizations that need sole use of servers to satisfy compliance requirements.
You may not, however, be aware that AWS also offers EC2 Bare Metal. This is essentially the same idea, except that with AWS EC2 Bare Metal, there is no virtualization software used. In other words, you get “pure” cloud infrastructure. This means that you can use them for applications that need non-virtualized environments, typically either for licensing reasons or because you need to squeeze the absolute maximum possible performance out of each server.