What is AWS EC2 (Elastic Compute Cloud)?
It’s an interface, based on web service, which supplies editable compute space in the AWS cloud. It is created so that developers can have total command over computing resources and web-scaling. You can resize EC2 Instances and scale their number up or down as you choose. You can launch them in single or multiple Availability Zones and geographical regions. Every region consists of multiple Availability Zones at different locations, linked by networks of a similar region having fast response time.

What is AWS EC2
What does EC2 Consist of?
EC2 is mainly made up of the following important elements:
- Error Tolerance and Consistency
It paves the way for users to create error-tolerant apps, in addition to containing geographic regions and remote locations called availability zones that tolerate fault occurrences and aim for consistency.
There is no sharing whatsoever of precise locations for security purposes. As soon as an instance is launched, the AMI chosen should be in the exact region where the instance will be running.
Instances are spread across various availability zones in order to deliver ongoing services even in the presence of failures, and Elastic IP addresses will swiftly point out failed instance addresses to simultaneous working instances found in different zones to evade any postponement.
- Privacy and Security
Total command over the visibility of AWS accounts is granted to the users. EC2’s security systems give way to the creation of groups and the placement of working instances into it as required.
The groups, that other groups communicate with, can be selected by the user, in addition to groups that internet IP subnets have the ability to talk to.
- Migration Service
It provides the users with the ability to transfer existing apps into EC2. The cost to get this service is 2.49$ to hour for data loading and 80$ to storage device. It mostly benefits users aiming to joggle a great amount of data for transfer.
- Operating System Support
There are various operating systems that are supported by EC2, but require the payment of further licensing fees, such as:
Oracle Enterprise Linux, Windows Server, Red Hat Enterprise, UNIX and SUSE Enterprise.
The implementation of those operating systems is required in combination with Amazon Virtual Private Cloud.
Setting Prices
It provides multiple pricing options relying on the kind of resources, the kind of apps and database. It gives users the ability to optimize their resources and calculate the expenses in accordance to that.
What are the Characteristics of EC2?
- Safe
It operates in a secure environment called Amazon Virtual Private Cloud which enables users to work in a safe and stable platform.
- Cost Effective
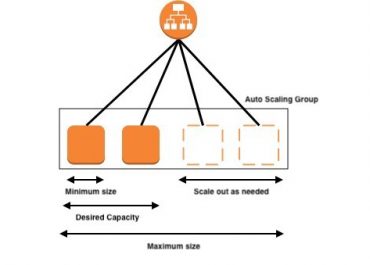
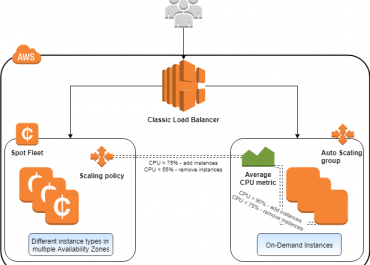
It only gets users to pay for the resources which they choose to perceive, and it consists of various purchasing plans like Reserved Instances, Spot Instances and Demand Instances, which can be chosen as needed.
- Credible
It provides the users with a reliable network where the change of instances can easily and quickly be made. The Service Level Agreement obligation is 99.9% availability for every EC2 region.
- Flexibility of Tools
It supplies the users with tools used by developers and system administrators for developing failure apps and staying far away as possible from any failures.
- Created for Amazon Web Services
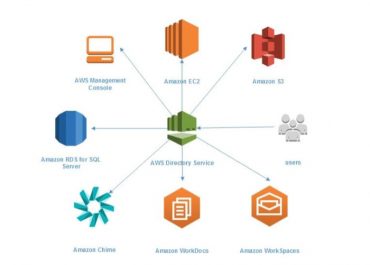
It operates perfectly well with the Amazon services such as Amazon DynamoDB, Amazon S3, Amazon SQS and Amazon RDS. It gives the users a total settlement for query processing, computing and storage over a vast variety of applications.
How is EC2 Used?
These are the steps needed to get to a successful launching and preparation method:
First: Log into your AWS account and go to the IAM console using this link: https://console.aws.amazon.com/iam/.
Second: Go to Navigation Panel and click on create/view groups and do as the instructions require of you.

AWS EC2 navigation
Third: Create an IAM user, click on users in the navigation pane, then go head and start creating new users and adding them to the groups.

EC2 navigation IAM user
Fourth: Start up a Virtual Private Cloud by following this process:
- Go to this link, https://console.aws.amazon.com/vpc/, to open Amazon VPC console.
- Click on VPC from the Navigation Panel, then choose the exact region you used when creating key-pair.

EC2 navigation panel
- Click “start VPC wizard” from the VPC dashboard.
- Choose VPC configuration page and check that VPC with single subnet is chosen. Then click on Select.
- A VPC with a single public subnet page is going to open, so now enter the VPC name in the name box and discard the rest of the configurations put as default.
- Choose “create VPC” and click “Ok”.
Fifth: Create WebServerSG security groups and add the rules by following this process:
- In the Navigation Panel of the VPC console, click on Security groups.
- Choose “create security group” and complete the required information (group name, name tag, etc.).

EC2 security group

EC2 create security group
- Choose your VPC ID from the menu, then click yes, create button.
- Right about now you can see that a group is created. Click the edit option in the inbound rules tab to start creating rules.
Sixth: Launch an EC2 Instance into VPC by following this process:
- Go to the EC2 console using this link: https://console.aws.amazon.com/ec2/.
- Click on Launch Instance from the dashboard.

EC2 launch instance
- Once a new page is opened, select Instance Type and fill the configuration, then click on Next: Configure Instance Details.
- Now another new page is opened, so choose VPC from the network list and click on subnet from the subnet list while keeping the other settings default.
- Click on Next, till the Tag Instances page shows up.
Seventh: When reaching the Tag Instances page, give a tag with a name to the instances, then click on Next: Configure Security Group.
Eighth: From the Configure Security Group page, click on “Select an existing security group option”. Choose the WebServerSG group which we had previously created, and then select Review and Launch.
Ninth: Review Instance details on the Review Instance Launch page, and choose the Launch button.
Tenth: When a pop-up dialog box opens, choose an existing key pair or create a new key pair. Later, click on the acknowledgement check box and click the Launch Instances button.