S3 Inventory Consistency
Not every single object will show in every inventory list.
It gives us consistency for PUTs of:
-New objects
-Overwrites
-DELETEs
Inventory lists may not have objects that are added or deleted at a recent time.
For the validation of object state before taking any action:
-Do a “HEAD Object” REST API request
-Get its metadata
-Check its properties in S3 console
-Check its metadata (with CLI or SDKS)
Inventory Lists’ Location:
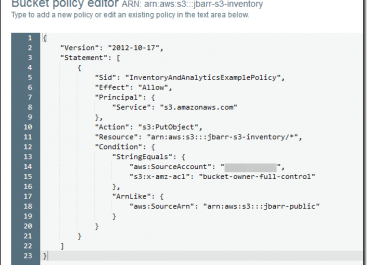
Upon the publishing of an inventory list, its manifest files go to the location in the destination bucket below.
destination-prefix/source-bucket/config-ID/YYYY-MM-DDTHH-MMZ/manifest.json
destination-prefix/source-bucket/config-ID/YYYY-MM-DDTHH-MMZ/manifest.checksum
destination-prefix/source-bucket/config-ID/hive/dt=YYYY-MM-DD-HH-MM/symlink.txt
destination-prefix/source-bucket/config-ID/YYYY-MM-DDTHH-MMZ/manifest.json
destination-prefix/source-bucket/config-ID/YYYY-MM-DDTHH-MMZ/manifest.checksum
- “destination-prefix”: object key name which can be added from the inventory configuration (used for grouping inventory list files in one common location found in the destination bucket).
- “source-bucket”:the bucket from which the inventory list was sent.
- “config-ID”:for the prevention of collisions between reports of various source buckets. It is received from the inventory report configuration (name for the report defined on setup).
- “YYYY-MM-DDTHH-MMZ”:it’s a timestamp which has a start time and a date of beginning for bucket scan (example: 2020-03-03T20-32Z).
- “manifest.json”:manifest file.
- “manifest.checksum”:MD5 of content found in json file.
- “symlink.txt”:Apache Hive-compatible manifest file.
They are published at a daily or weekly frequency to the location below in destination bucket.
destination-prefix/source-bucket/config-ID/example-file-name.csv.gz
destination-prefix/source-bucket/config-ID/example-file-name-1.csv.gz
- “destination-prefix”:is the (object key name) prefix set in the inventory configuration. It can be used to group all the inventory list files in a common location in the destination bucket.
- “source-bucket”:is the source bucket that the inventory list is for. It is added to prevent collisions when multiple inventory reports from different source buckets are sent to the same destination bucket.
- “example-file-name.csv.gz”:a CSV inventory file.
ORC inventory names: end with “.orc” extension
Parquet inventory names: end with “.parquet” extension
Inventory Manifest:
The manifest files: “manifest.json and symlink.txt” do the following
-Describe the location of inventory files
-Accompany a newly delivered inventory list
-Manifests found in the manifest.json file give metadata and information related to an inventory, which includes the below:
- “Source Bucket Name”
- “Destination Bucket Name”
- “Version of Inventory”
- “Creation timestamp” (epoch date format: start time + date for the start of bucket scanning
- “Format + schema” of inventory files
- “Actual list” of inventory files in destination bucket
manifest.json file gets a manifest.checksum file (as the MD5 of content found in manifest.json file)
Example of a manifest found in a manifest.json file (CSV-formatted inventory):
{
"sourceBucket": "example-source-bucket",
"destinationBucket": "arn:aws:s3:::example-inventory-destination-bucket",
"version": "2016-11-30",
"creationTimestamp" : "1514944800000",
"fileFormat": "CSV",
"fileSchema": "Bucket, Key, VersionId, IsLatest, IsDeleteMarker, Size, LastModifiedDate, ETag, StorageClass, IsMultipartUploaded, ReplicationStatus, EncryptionStatus, ObjectLockRetainUntilDate, ObjectLockMode, ObjectLockLegalHoldStatus",
"files": [
{
"key": "Inventory/example-source-bucket/2016-11-06T21-32Z/files/939c6d46-85a9-4ba8-87bd-9db705a579ce.csv.gz",
"size": 2147483647,
"MD5checksum": "f11166069f1990abeb9c97ace9cdfabc"
}
]
}
{
"sourceBucket": "example-source-bucket",
"destinationBucket": "arn:aws:s3:::example-inventory-destination-bucket",
"version": "2016-11-30",
Example of a manifest found in a manifest.json file (ORC-formatted inventory):
{
"sourceBucket": "example-source-bucket",
"destinationBucket": "arn:aws:s3:::example-destination-bucket",
"version": "2016-11-30",
"creationTimestamp" : "1514944800000",
"fileFormat": "ORC",
"fileSchema": "struct<bucket:string,key:string,version_id:string,is_latest:boolean,is_delete_marker:boolean,size:bigint,last_modified_date:timestamp,e_tag:string,
storage_class:string,is_multipart_uploaded:boolean,replication_status:string,encryption_status:string,object_lock_retain_until_date:timestamp,object_lock_mode:string,object_lock_legal_hold_status:string>",
"files": [
{
"key": "inventory/example-source-bucket/data/d794c570-95bb-4271-9128-26023c8b4900.orc",
"size": 56291,
"MD5checksum": "5925f4e78e1695c2d020b9f6eexample"
}
]
}
{
"sourceBucket": "example-source-bucket",
"destinationBucket": "arn:aws:s3:::example-destination-bucket",
"version": "2016-11-30",
"creationTimestamp" : "1514944800000",
"fileFormat": "ORC",
Example of a manifest found in a manifest.json file (Parquet-formatted inventory):
{
"sourceBucket": "example-source-bucket",
"destinationBucket": "arn:aws:s3:::example-destination-bucket",
"version": "2016-11-30",
"creationTimestamp" : "1514944800000",
"fileFormat": "Parquet",
"fileSchema": "message s3.inventory { required binary bucket (UTF8); required binary key (UTF8); optional binary version_id (UTF8); optional boolean is_latest; optional boolean is_delete_marker; optional int64 size; optional int64 last_modified_date (TIMESTAMP_MILLIS); optional binary e_tag (UTF8); optional binary storage_class (UTF8); optional boolean is_multipart_uploaded; optional binary replication_status (UTF8); optional binary encryption_status (UTF8);}"
"files": [
{
"key": "inventory/example-source-bucket/data/d754c470-85bb-4255-9218-47023c8b4910.parquet",
"size": 56291,
"MD5checksum": "5825f2e18e1695c2d030b9f6eexample"
}
]
}
{
"sourceBucket": "example-source-bucket",
"destinationBucket": "arn:aws:s3:::example-destination-bucket",
"version": "2016-11-30",
"creationTimestamp" : "1514944800000",
"fileFormat": "Parquet",
"fileSchema": "message s3.inventory { required binary bucket (UTF8); required binary key (UTF8); optional binary version_id (UTF8); optional boolean is_latest; optional boolean is_delete_marker; optional int64 size; optional int64 last_modified_date (TIMESTAMP_MILLIS); optional binary e_tag (UTF8); optional binary storage_class (UTF8); optional boolean is_multipart_uploaded; optional binary replication_status (UTF8); optional binary encryption_status (UTF8);}"
-“symlink.txt” Apache Hive-compatible manifest file can’t work with Glue.
-“symlink.txt” with Apache Hive and Apache Spark does not work with ORC and Parquet inventory files.
Knowing an Inventory Is Complete:
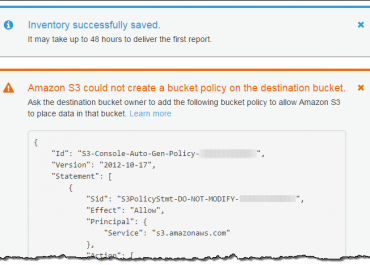
-By setting an S3 event notification you can easily get a notice that the manifest checksum file has been created.
-This will let you know that an inventory list was sent to your destination bucket.
-Manifest: up-to-date list showing every single inventory list found in your destination location.
Events get published to:
-A Simple Notification Service (SNS) topic
-A Simple Queue Service (SQS) queue
-A Lambda function
Below is an example of a notification configuration which states that all manifest.checksum files that have recently been added to a given destination bucket will get processed by: Lambda cloud-function-list-write.
<NotificationConfiguration>
<QueueConfiguration>
<Id>1</Id>
<Filter>
<S3Key>
<FilterRule>
<Name>prefix</Name>
<Value>destination-prefix/source-bucket</Value>
</FilterRule>
<FilterRule>
<Name>suffix</Name>
<Value>checksum</Value>
</FilterRule>
</S3Key>
</Filter>
<Cloudcode>arn:aws:lambda:us-west-2:222233334444:cloud-function-list-write</Cloudcode>
<Event>s3:ObjectCreated:*</Event>
</QueueConfiguration>
</NotificationConfiguration>
<NotificationConfiguration>
Athena for Querying Inventory
S3 inventory can be queried through standard SQL by Athena (in every Region that Athena is available at).
S3 inventory files can be queried by Athena in the following formats:
-ORC
-Parquet
-CSV
It’s advised to use ORC-formatted or Parquet-formatted inventory files with Athena querying.
They give: quicker query performance and less query costs.
ORC and Parquet are:
– Self-describing
– Type-aware
– Columnar file formats
– Designed for Apache Hadoop
– Allow the reader to process, read and decompress the current query required columns only.
– Are available in all Regions.
To use Athena for querying S3 inventory follow the steps below:

aws s3 consistency
- Start off by creating an Athena table.

aws s3 consistency – athena table

aws s3 consistency – add athena table
This example query has every optional field in an inventory report which is of an ORC-format. Delete whatever optional field not chosen for your inventory. Write the bucket name and the location that you are using, which shows the destination path of your inventory. Example: “ s3://destination-prefix/source-bucket/config-ID/hive/ ” .

aws s3 consistency – input data set
CREATE EXTERNAL TABLE your_table_name(
`bucket` string,
key string,
version_id string,
is_latest boolean,
is_delete_marker boolean,
size bigint,
last_modified_date timestamp,
e_tag string,
storage_class string,
is_multipart_uploaded boolean,
replication_status string,
encryption_status string,
object_lock_retain_until_date timestamp,
object_lock_mode string,
object_lock_legal_hold_status string
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://destination-prefix/source-bucket/config-ID/hive/';
For querying a Parquet-formatted inventory report: you must rely on this Parquet SerDe instead of ORC SerDe for the “ROW FORMAT SERDE” statement.

aws s3 consistency – data format
ROW FORMAT SERDE ‘org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe’
- For adding to the table some more inventory lists, type this “MSCK REPAIR TABLE”
MSCK REPAIR TABLE your-table-name;
- When the first two steps are done, start running “ad hoc queries” on your inventory, like the below examples.
# Get list of latest inventory report dates available
SELECT DISTINCT dt FROM your-table-name ORDER BY 1 DESC limit 10;
# Get encryption status for a provided report date.
SELECT encryption_status, count(*) FROM your-table-name WHERE dt = 'YYYY-MM-DD-HH-MM' GROUP BY encryption_status;
# Get encryption status for report dates in the provided range.
SELECT dt, encryption_status, count(*) FROM your-table-name
WHERE dt > 'YYYY-MM-DD-HH-MM' AND dt < 'YYYY-MM-DD-HH-MM' GROUP BY dt, encryption_status;
# Get list of latest inventory report dates available
REST APIs
The below listed are REST operations for S3 inventory:
- DELETE Bucket
- GET Bucket
- List Bucket
- PUT Bucket